我总是嫌弃读书的速度态度,吸收知识太慢,然后反过来就觉得有些气馁。殊不知冰冻三尺非一日之寒,滴水石穿又岂是一朝之功。看书本来就是缩短通过工作来学习 的周期,本来就是把大量知识压缩为一点。这个时候只怕是囫囵吞枣消化不良,怎能够再贪图速度呢。
自己看了《鸟哥Linux私房菜》也有一阵子了,书好歹也看了一大半了,然后回想一下,能记忆起来的确实寥寥。如我看完书就忘记,那我还何必要看书? 如果我自己做的笔记从来不看,那我又何必要做?为了强化自己,所以要把之前每章的内容再梳理一遍。重在层次结构,重在知识点的联系,重在分析。
书要先读薄,再读厚才对。
思路分析
因为本章节是从细节上深入讲解整个磁盘和文件系统的,所以,文章开始是梳理整个磁盘宏观上的结构成分。
整颗磁盘的组成有:
- 圆形的磁盘盘(主要记录数据的部分)
- 机械手臂, 与在机械手臂上的磁盘都去头(可擦写磁盘盘上的数据)
- 主轴马达,可以转动磁盘盘,让机械手臂的读取头在磁盘盘上读写数据。
磁盘盘上的物理组成则为:(假设磁盘为单盘片)
- 扇区(Sector)为最小的物理存储单位,每个扇区为 512 bytes
- 将扇区组成一个圆,那就是磁柱(Cylinder),磁柱是分割槽(partition)的最小单位;
- 第一个扇区最重要,里面有:(a)主要开机区(Master boot record, MBR)及分个表(partition table), 其中 MBR 占有 446 bytes,而 partition table 则占有 64 bytes。
磁盘分区(即 A 磁柱到 B 磁柱的块)
- 主要分区与扩展分区最多可以有 4 笔(硬盘的限制)
- 扩展分区最多只能有一个(操作系统的限制)
- 逻辑分区是由扩展分区进一步分区出来的分区槽
- 能够被格式化后,作为数据存取的分割槽为主要分割与逻辑分割。扩展分区无法格式化
- 逻辑分区的数量依操作系统而不同,在 linux 系统中, IDE 硬盘最多有 59 个逻辑分割(5 号到 63 号),SATA 硬盘则有 11 个逻辑分割(5 号到 15 号)。
然后开始讲解系统特性,其核心在于一句话
每种操作系统能够使用的文件系统并不相同,所以在磁盘分区完后要进行格式化,成为对应的文件系统才能够被其使用。
自然而然开始讲解文件系统的构成(ext2)
文件系统通常包含两部分:权限和属性,实际数据,分别存放于 inode 和 data block 中。另外还有一个 superblock 会记录整个文件系统的整体信息,包括 inode 与 block 的总量 ,使用量,剩余量等。 每个 inode 与 block 都有编号,意义如下: 1. superblock: 记录此 filesystem 的整体信息,包括 inode/block 的总量,使用量,剩余量,以及文件系统的格式与相关信息等。 2. inode: 记录档案的属性,一个档案占用一个 inode, 同时记录此档案的数据所在的 block 号码; 3. block: 实际记录档案的内容,若档案太大时,会占用多个 block。
这个有个 碎片整理 概念,需要碎片整理的原因就是 block 太过离散了,此时读取的效能就会很差。碎片整理的目的就是把同一个文档的 block 都尽量汇聚到一起。不过这里也可以看到,
对于 ext2 这种索引式文件系统,相对来说不太需要碎片整理的,因为它是一次性在 inode 中读入所有的 block 的。
接下来具体讲解 data block

Ext2 文件系统的 block 限制: 1. 原则上, block 的大小与数量在格式化完就不能够再改变了(除非重新格式化) 2. 每个 block 内最多只能狗放置一个档案的数据; 3. 承上,如果档案大于 block 的大小,则要给档案会占用多个 block 数量 4. 承上,若档案小于 block,则该 block 的剩余容量就不能够再被使用了(磁盘空间会浪费)
这里就需要思考,那么是不是把 block 分的越小越好?当然也不是,因为 block 太小,大文件会占用太多 block,而 inode 也要记录更多 block 号码,将导致文件系统不良的读写效能。
讲完 block,自然就是 inode 了。
inode 记录内容:
- 该档案的存取模式(read/write/excute)
- 该档案的拥有者与群组(owner/group)
- 该档案的容量
- 该档案建立或状态改变的时间(ctime)
- 最近一次的读取时间(atime)
- 最近修改的时间(mtime)
- 定义档案特性的旗标(flag),如 Set UID…
该档案真正内容的指向
inode 的特点:
- 每个 inode 大小均固定为 128 bytes
- 每个档案都仅会占用一个 inode 而已
- 承上,因此文件系统能够建立的档案数量与 inode 的数量有关
- 系统读取档案时需要先找到 inode,并分析 inode 所记录的权限与用户是否符合,若符合才能够开始实际读取 block 的内容。
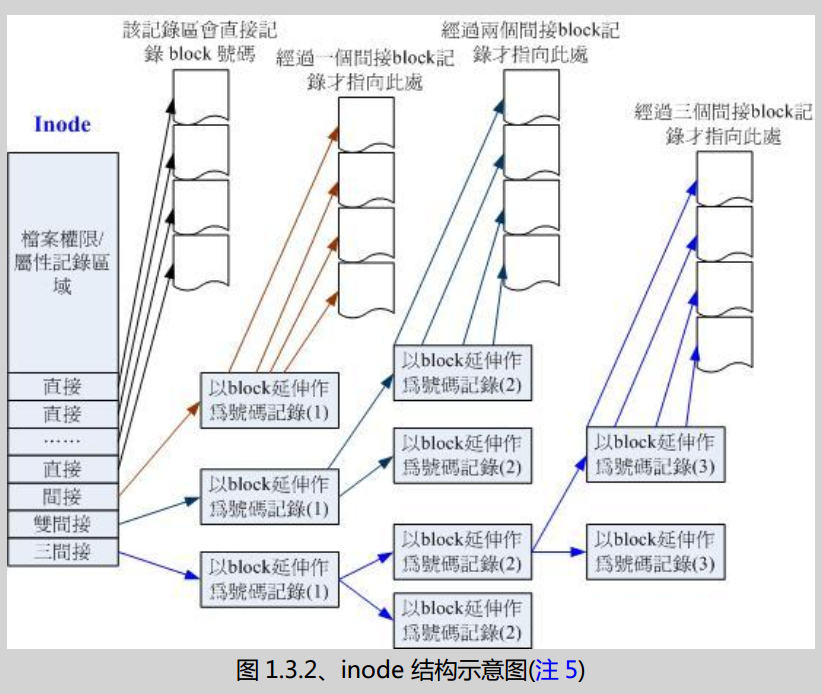
但毕竟 inode 只有 128 bytes,如果不够用怎么办?为此我们的系统很聪明的将 inode 记录 block 号码的区域定义为 12 个直接,一个间接,一个双间接,一个三 间接,如图所示。从这里也可以计算出来上图 block 大小和最大单一档案限制的关系。以 block 为 1k 为例, 12 + 256 + 256 * 256 + 256 * 256 * 256 = 16 GB
接下来就是 Superblock (超级区块)
Superblock 是记录整个 filesystem 相关信息的地方, 没有 Superblock, 就没有这个 file system了,他记录的信息主要有:
- block 与 inode 的总量
- 未使用与已使用的 inode/block 数量
- block 与 inode 的大小(block 为 1,2,4K,inode 为 128 bytes)
- filesystem 的挂载时间、最近一次写入数据的时间、最近一次检验磁盘(fsck)的时间等文件系统的相关信息
- 一个 valid bit 数值,若此文件系统已被挂载,则 valid bit 为 0,若未被挂载,则 valid bit 为 1
以上即为 ext2 基础内容,具体又是如何读取文档数据呢?以 /etc/passwd 为例:
- / 的 inode: 透过挂载点的信息找到 /dev/hdc2 的 inode 号码为 2 的根目录 inode, 且 inode 规范的权限让我们可以读取该 block 的内容(有 r 与 x)
- / 的block: 经过上个步骤取得 block 的号码,并找到该内容有 etc/ 目录的 inode 号码(1912545);
- etc/ 的 inode 读取 1912545 号 inode 得知 vbird(账号)具有 r 与 x 的权限,因此可以读取 etc/ 的 block 内容;
- etc/ 的block 经过上个步骤取得 block 号码,并找到该内容有 passwd 档案的 inode 号码(1914888);
- passwd 的 inode 读取 1914888 号 inode 得知 vbird 具有 r 的权限,因此可以读取 passwd 的block内容;
- passwd 的block 最后将该 block 内容的数据读出来
上面是读取,如果新建, ext2 又是如何处理的呢?
首先,需要用到 block bitmap(区块对照表) 与 innode bitmap (inode 对照表),说白了,这两个表就是判断那些 block,inode 是可用的。
- 先确定用户对于欲新增档案的目录是否具有 w 与 x 的权限,若有的话才能新增;
- 根据 inode bitmap 找到没有使用的 inode 号码,并将新档案的权限/属性写入;
- 根据 block bitmap 找到没有使用中的 block 号码,并将实际的数据写入 block 中,切更新 inode 的 block 指向数据;
- 将刚刚写入的 inode 与 block 数据同步更新 inode bitmap 与 block bitmap, 并更新 superblock 的内容。
以上是正常情况下,inode 与 block 的处理情况。那么系统突然中断,写入的数据仅有 inode table 和 data block,最后的同步没有完成怎么办? 这个时候就要用到 日志式文件系统(Journaling filesystem),其检查步骤如下;
- 预备:当系统要写入一个档案时,会先在日志记录区块中记录某个档案准备要写入的信息;
- 实际写入:开始写入档案的权限与数据;开始更新 metadata 的数据;
- 结束: 完成数据与 metadata 的更新后,在日志记录区块当中完成该档案的记录。
还有一种情况是当我们编辑一个很大的文档,编辑的过程中又要频繁的写入磁盘中(比如保存,而编辑这个动作本身是在内存中),由与磁盘写入的速度要比内存慢很多,那么 我们会在等待硬盘的写入/读取上耗费很多时间,这样显然就很没有效率。linux 使用异步处理(asynchronous)的方式,来处理这张情况。即
当系统加载一个档案到内存后,如果该档案没有被更动过,则在内存区段的档案数据会被设定为干净(clean)的。但如果内存中的档案数据被更改过了,此时该内存中的 数据会被设定为脏的(dirty)。此时所有的动作都还在内存中执行,并没有写入到磁盘中!系统会不定时的将内存中设定为 dirty 的数据写回磁盘,以保持磁盘与内存数据的 一致性。
linux 系统上面文件系统与内存有非常大的关系:
- 系统会将常用的档案数据放置到主存储器的缓冲区,以加速文件系统的读/写
- 承上,因此 Linux 的物理内存最后都会被用光!这是正常的情况!可加速系统效能
- 你可以手动使用 sync 来强迫内存中设定为 Dirty 的档案回写到磁盘中
- 若正常关机时,关机指令会主动呼叫 sync 来将内存的数据回写如磁盘内
- 若不正常关机,由于数据尚未回写到磁盘内,因此重新启动后可能会花很多时间在进行磁盘检验,甚至可能导致文件系统的损毁。
挂载点的意义
首先我们要明白,文件系统彼此之间是独立的,所以可能两个不同的文档有相同的 inode 号,这是因为她们属于不同的 filesystem 的原因。而每个 filesystem 都有独立的 inode/block/
superblo 等信息,这个文件系统要能够链接到目录树才能被我们使用。这个动作即是挂载。
其他 LInux 支持的文件系统与 VFS 文件系统有多种,传统文件系统、日志式文件系统、网络文件系统。那么 linux 的核心又是如何管理这些认识的文件系统呢?整个 Linux 的系统就是通过一个名为 Virtual Filesystem Switch 的核心功能去读取 filesystem 的。也就是说,整个 Linux 认识的 filesystem 其实就是 VFS 在进行管理,而我们使用者并不需要知道每个 partition 上的 filesystem 是什么,该用什么 模块去读取,这个 VFS 会帮我们做好。
两个命令:
df: 列出文件系统的整体磁盘使用量
du: 评估文件系统的磁盘使用量(常用在推估目录所占容量)
这里相当于第二部分了,讲了 inode 与 block 的一些用处。
实体链接与符号链接: In
实体链接(Hard Link) 由上面的信息,我们可知:
- 每个档案都会占用一个 inode,档案内容由 inode 的记录来指向
- 想要读取该档案,必须经过目录记录的文件名(文件名信息记录在目录中)来指向到正确的 inode 号码才能读取。
即文件名本身只和目录相关,和 inode 并没有什么必然对应关系。因此一个 inode 可以被连接到不同的文件名,这个即是硬链接。
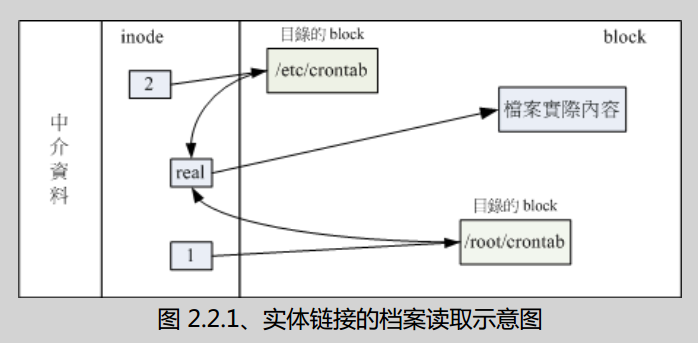
图示,文件夹对应的 inode 为 1,2,分为找到对应的block内容,定位到文件,两个文件都则都连接到同一个 inode(real)。
hard link的限制:
- 不能跨 filesystem
- 不能 link 目录
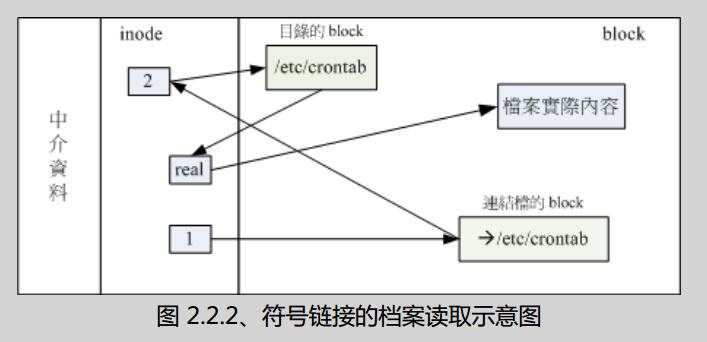
符号链接(快捷方式,Symbolic Link)
磁盘的分割、格式化、检验与挂载
fdisk、mkfs、mke2fs、fsck、badblocks
mount、umount
这一块挂载因为不涉及原理,从简了。